
Forum Replies Created
-
AuthorPosts
-
It seems the added nic can’t survive a reboot.
I rebooted node2 in that slice. I can still login to it via the management ip which is good. Also the nvme device is still in the node. The problem is eth1 is gone after reboot.
Hi Mert,
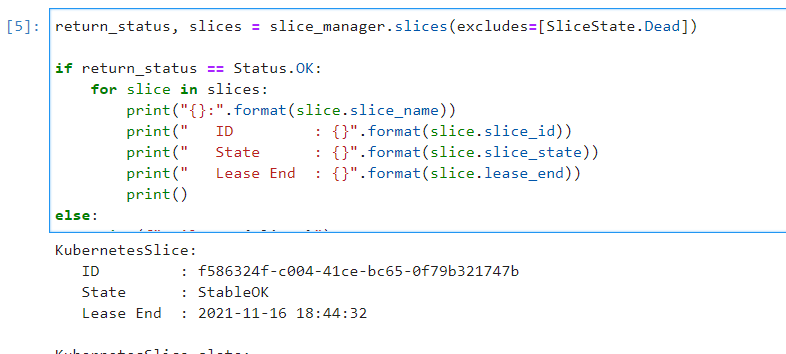
I’ve created a new slice: KubernetesSlice1 at site MAX. Management ip for node1 is 63.239.135.80. I also extended the lease for it.
The NetworkManager is enabled with eth1 and calico interfaces excluded.
Would you be able to check how this slice look. The big question is if it can stay like that after 1 day without losing it’s network interface etc.
Thanks,
Fengping
Hi Mert,
Thanks for looking into this for us. So somehow the vm is restarted and lost the network configurations. We will make changes to let eth0 be managed by the NetworkManager so it can survive a reboot.
But it looks not just the configuration is lost, also a network interface disappeared. The vm is created with a second interface eth1. But that interface no longer exist. We need the second interface to form a cluster.
[centos@node1 ~]$ sudo ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether fa:16:3e:49:8e:5a brd ff:ff:ff:ff:ff:ff
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:69:1f:14:22 brd ff:ff:ff:ff:ff:ff
[centos@node1 ~]$Any idea on how to address the second issue?
Thanks,
Fengping
It looks I am seeing the same problem at NCSA. My slice there also lost contact after 1 day despite lease extensions. We will try to improve deployment automations while these hiccups are being addressed:)
~$ ping 141.142.140.44
PING 141.142.140.44 (141.142.140.44) 56(84) bytes of data.
From 141.142.140.44 icmp_seq=1 Destination Host UnreachableHi Ilya, Thanks for letting me know. I’m spinning one up in NCSA. I will let you know if I see the same problem at NCSA.
Thanks for looking into this for me.
Yes, I was able to access this slice perfectly fine. I deployed this slice on Nov 11th. I have installed kubernetes on it and was able to deploy some applications on the kubernetes cluster and access the application via internet(via ingress through the management ip) on Friday.
I also extended the lease of this slice for 30 days.
I found it no longer accessible this morning. I have not done anything to the slice over the weekend.
Slice active but node no longer accessible happened again. My slice is on site MAX. Please let me know if there’s anything I can do to regain access. Thanks!
KubernetesSlice-slate:
ID : 9d7ee6d2-1db0-4e2c-a513-6b89801f7ed3
State : StableOK
Lease End : 2021-11-12 22:01:58They are all at the MAX site. The names are something like KubernetesSlice, MyKubernetesSlice, KubernetesSlice-test. Not 100% sure about the names anymore since I didn’t keep it.
Yes I had about 3 active slices and a few dead ones. Now they are all gone.
I will create a new slice for the slate fabric project. Let me know if I need to do anything to the nodes that are still alive. Guess they will still die after lease end even though the slice is not returned from query.
Here are the management ips :
63.239.135.116, 63.239.135.87
63.239.135.75, 63.239.135.121(these two seems just died since there are created this time yesterday)
seems I have a opposite problem today. I am getting slice not found, even though I can still login to the node.
This is a slice I created yesterday during slate fabric working sessions. I have been trying to extend the lease of this slice since yesterday. It was blocked due to timeout to get the slice at first which I attribute to maintenance. But now the Max is announced to be up and what I am getting is the slice can’t be found. Should I give up this slice and just create a new one?
Failure: (404)
Reason: NOT FOUND
HTTP response headers: HTTPHeaderDict({‘Server’: ‘nginx/1.21.1’, ‘Date’: ‘Thu, 11 Nov 2021 21:25:33 GMT’, ‘Content-Type’: ‘text/html; charset=utf-8’, ‘Content-Length’: ’19’, ‘Connection’: ‘keep-alive’, ‘Access-Control-Allow-Credentials’: ‘true’, ‘Access-Control-Allow-Headers’: ‘DNT, User-Agent, X-Requested-With, If-Modified-Since, Cache-Control, Content-Type, Range’, ‘Access-Control-Allow-Methods’: ‘GET, POST, PUT, DELETE, OPTIONS’, ‘Access-Control-Allow-Origin’: ‘*’, ‘Access-Control-Expose-Headers’: ‘Content-Length, Content-Range, X-Error’, ‘X-Error’: ‘User# has no Slices’})
HTTP response body: User# has no SlicesFYI
Looks I can login to the nodes again today. However the node is changed. for example, the kubernetes installation are gone.
-
AuthorPosts